AI大神李沐:创业一年,人间三年
李沐——湖南师大附中2024届高0101班校友。BosonAI 的联合创始人,曾担任亚马逊首席科学家。从 Amazon 离职后,他投身于大语言模型(LLM)的创业项目,经历了融资的波折、技术挑战和市场探索后,终于迎来柳暗花明又一村,在创业第一年实现了收支平衡。他将自己的创业经历汇成《创业一年,人间三年》一文,分享了其创业第一年的进展、挑战和反思。以下是李沐的自述,原文来自李沐的知乎及 B 站专栏,本文有所改动。
 其实在 Amazon 待到第 5 年的时候,我就想开始创业了,但当时疫情的爆发阻碍了我的计划。到了第 7 年半,心中对于创业的渴望越来越强烈,于是我便提出了离职,投身创业。
其实在 Amazon 待到第 5 年的时候,我就想开始创业了,但当时疫情的爆发阻碍了我的计划。到了第 7 年半,心中对于创业的渴望越来越强烈,于是我便提出了离职,投身创业。
现在回想起来,我觉得,**如果生命中有什么事情是注定要尝试的,那么越早开始越好。**因为一旦真正踏上创业之路,你会发现有无数新知识需要学习,所以我常常感叹,自己为何没有更早开始创业。
BosonAI 的来源
在创业之前,我参与了一系列以“Gluon”命名的项目。在量子物理学中,Gluon 是一种将夸克紧密结合的玻色子,项目命名为“Gluon”象征着项目起初是 Amazon 和 Microsoft 的联合项目。
“Gluon”这个名字是当时的项目经理的灵机一动,但取名对程序员来说很困难。创业之初,我们每天都在纠结各种文件名和变量名,最后新公司干脆就用玻色子(Boson)来命名,希望人们在理解到“Boson 和费米子组成了世界”这个梗时会会心一笑。然而出乎意料的是,许多人会误将其看成“Boston”。(笑)
“我来 Boston 了,找个时间碰碰?” “哈?可我在湾区呀😅”
融资:签字前一天领投方跑路
在 2022 年年底,我脑海中闪现了两个利用大语言模型(LLM)做生产力工具的想法。刚好我在机缘巧合之下遇到了张一鸣,于是就向他请教。经过一番讨论之后,他反问我:“为什么不做 LLM 本身呢?”
我本能地退缩,表示自己因为之前在 Amazon 的团队做了好几年 LLM,面对的是数以万计的显卡,以及一系列繁复的挑战。然而,张一鸣回应我:“这些都是短期困难,眼光得看长远点。”
我的优点是听劝,于是我就投身于 LLM 的开发中了。我们迅速组建了一支由数据、预训练、后训练以及架构等关键领域的负责人构成的创始团队,然后就开始准备融资。幸运的是,我们很快拿到了种子投资。然而,这笔资金还不足以支持我们购买所需的显卡。我们迫切需要进行第二轮融资。
在第二轮融资中,我们得到了一家极具规模的机构的领投承诺,为此我们投入了数月时间,用来准备文档和协商条款。结果就在我们即将签署协议的前一天,领投方突然宣布停止投资,这直接导致其他几家跟投方的退出。幸好还有剩下的投资方,我们很感激他们支持我们完成了第二轮融资,让我们最终获得了进入 LLM 领域的入场券。
如今再来反思当时,其实如果当初能够趁着资本市场的热情尚在,继续融资,或许今天我们也能像其他友商一样,手握十亿现金。不过当时我也是考虑到融资过多,会让之后的退出市场变得困难,会被裹挟。但现在看来,创业就是想逆天改命,需要破釜沉舟,想什么退路呢?
机器:第一批吃螃蟹的人
融资资金到位后,我们就去买 GPU,问过各个供应商后得到统一回复: H100 交货得一年以后了。面对这一困境,我灵机一动,决定直接给 NVIDIA 的 CEO 黄仁勋(Jensen Huang)发送邮件。意想不到的是,我很快得到了他的回复。仅仅过去 1 小时,超微的 CEO 便主动打来电话。最终,我们通过支付了一些额外费用,20 天后便收到了所需的机器,因此早早“吃到了螃蟹”。
不过这“螃蟹”也让我们吃到怀疑人生,遇到了各种匪夷所思的 bug。例如 GPU 供电不足导致不稳定,后来靠超微工程师修改 bios 代码打上补丁才解决;例如光纤的切开角度不对,导致通讯不稳定;例如 NVIDIA 的推荐网络布局不是最优,于是我们重新做了一个方案,后来 NVIDIA 也采用了这个方案。至今我都不理解,我们就买了不到一千张卡,算小买家,但我们遇到的这些问题,难道大买家没遇到吗,为啥需要我们的 debug?
同时我们还租了同样多的 H100,也遇到了各种各样的 bug,GPU 每天都出问题。我们一度怀疑,是不是这个云上就我们一家吃“螃蟹”的公司。直到后来,我们看见了 Llama3 的技术报告,他们声称改用 H100 后,训练一次模型被打断几百次,我们对此很是共情。
对比自建和租卡,以三年为期,租用和自建的成本差异不大。租卡的好处是省心,而自建的好处有两个:第一,如果三年后 NVIDIA 的技术还遥遥领先,那么它能控制价格使得 GPU 仍然保值;第二,自建的数据存储成本低。存储需要跟 GPU 比较近,无论是大云还是小 GPU 云,存储价格都高。但一次模型训练可以用几 TB 空间存 Checkpoint,训练数据存储是 10PB 起跳。如果用 AWS S3 的话,10PB 一年需要两百万,这钱如果用来自建,可以用上 100PB。
商业:感恩客户,第一年收支平衡
值得庆幸的是,我们在第一年就实现了收支平衡。**我们的支出主要消耗在人力和算力上,收入来源是给大客户做定制模型。**很早就上 LLM 的公司的 CEO 大都非常有决策力,他们没被高昂的算力和人力成本吓到,果断地选择我们,去共同推动其内部团队配合尝试新技术。我们非常感恩这些客户给了我们机会,让我避免再次奔波在各个投资人那里。
接下来应该会有更多公司开始尝试使用 LLM,无论是用于自己产品的升级,还是为了降本增效。如今一方面技术成本在降低,另一方面行业领先者(例如我们客户)会陆续放出基于 LLM 的产品,卷动了行业。
同时我们也在关注 LLM 在 ToC 上的落地。上一波顶流例如 Character.AI 和 Perplexity AI 还在找商业模式,但也有小十来家 LLM 原生应用收入可观。我们给一家做角色扮演的创业公司提供了模型,他们主打深度的玩家,打平了收入和支出,也很厉害。另外模型能力还在持续进化,更多模态(语音、音乐、图片、视频)在融合,相信接下来还会有更有想象力的应用出现。
放眼整个市场,行业和资本还是有些急不可耐,今年有好几家成立一年多但融资上十亿的公司选择了退出**。其实从技术到产品,本身就是一个需要花费很长时间的过程,两到三年实属正常。算上用户的需求的涌现,可能得花更长时间。我们对此的态度是:专注当下,在迷雾中探路,对未来保持乐观。**
技术:LLM 认知的四个阶段
我对 LLM 的认知经历了四个阶段:
第一阶段是 BERT 到 GPT-3,我的感受是新架构、大数据可以做。我们在 Amazon 的时候,也是第一时间做了大规模的训练和在产品上的落地。
第二阶段是我刚创业的时候 ,GPT-4 现世,让我大受震撼,一大半原因是技术不公开了。根据小道消息估算,一次模型训练花费一个亿,标数据成本耗费几千万。很多投资人问我复现 GPT-4 的成本大概多少,我估计是 3-4 亿。后来他们中有一家真一次性投了大几亿出去。
第三阶段是我创业的第一个半年。那时我们做不动 GPT-4,于是就想着从具体的问题出发。我们开始找各行各业的客户,包含游戏、教育、销售、金融、保险等,针对他们的具体需求去训练模型。起初市面上没有好的开源模型,所以我们就自己从头开始训练。后来很多很好的模型面世了,也降低了我们的成本。然后我们就针对业务场景设计评估方法,标数据,去看模型哪些地方欠缺,从而进行针对性提升。
到 2023 年年底时,我们惊喜地发现,我们的 Photon(Boson 的一种)系列模型,在客户应用上的效果胜过 GPT-4 了。定制模型的好处是推理成本是调用 API 的 1/10。虽然今天 API 已经便宜很多,但我们自己的技术也同样在进步,所以仍然是 1/10 成本。另外,QPS、延时等都更好控制。这个阶段的认知是对于具体应用,而我们是可以打赢市面上最好模型的。
第四阶段是创业的第二个半年。虽然我们让客户拿到了满足合同需要的模型,但还不是他们理想中的东西,因为 GPT-4 还远不够。年初时我们发现针对单一应用训练,模型很难再次飞跃。转念一想,如果 AGI 是达到了普通人类水平,那么客户要的就是专业人士水平。游戏行业要专业策划和专业演员、教育行业要金牌老师、销售行业要金牌销售、金融保险行业要高级分析师,这些都需要 AGI 加上行业专业能力。虽然当时我们内心对 AGI 充满敬畏,但感觉这个过程是避不开的。
我们在年初设计了 Higgs(上帝粒子,Boson 的一种)系列模型,主打通用能力紧跟最好的模型,但在某个能力上突出。我们挑选的能力是角色扮演:扮演虚拟角色、扮演老师、扮演销售、扮演分析师等等。2024 年年中的时候迭代到第二代,在测试通用能力的 Arena-hard 和 AlpacaEval 2.0 上,v2 跟最好的模型打得有来有回,在测试知识的 MMLU-pro 上也相差无几。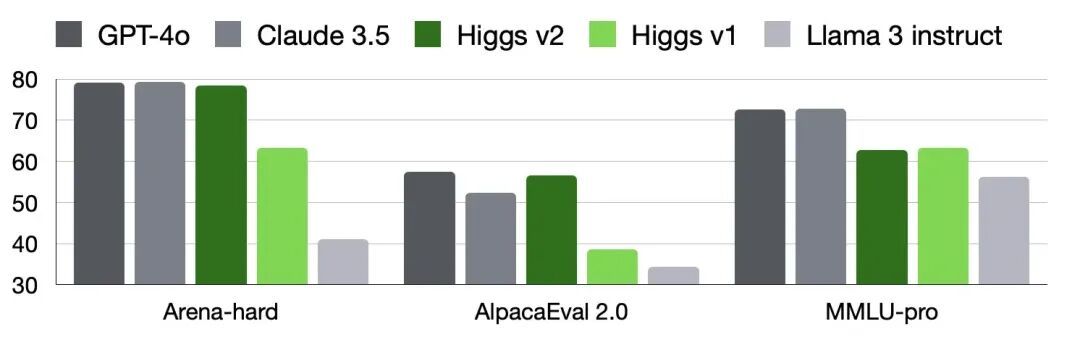
Higgs v2 是基于 Llama 3 base,然后做了完整的 post-training。我们无法像 Meta 那样花大钱标注数据,所以 v2 比 Llama 3 instruct 好,主要原因应该还是来自算法的创新。
然后我们做了一个评估角色扮演的评测集,包含按照人设扮演和按照场景扮演。我们自己的模型在自己的榜单上拿了第一,但模型训练中是没有碰评测用的数据的。因为这个评测集一开始就是想自用,希望能真实反映模型能力,所以要避免模型 overfit 数据集。但做评测的同学想写技术报告,所以公开放出来了。有意思的是,按角色扮演的测试样本来自 Character.AI,但他们家的模型能力是垫底的。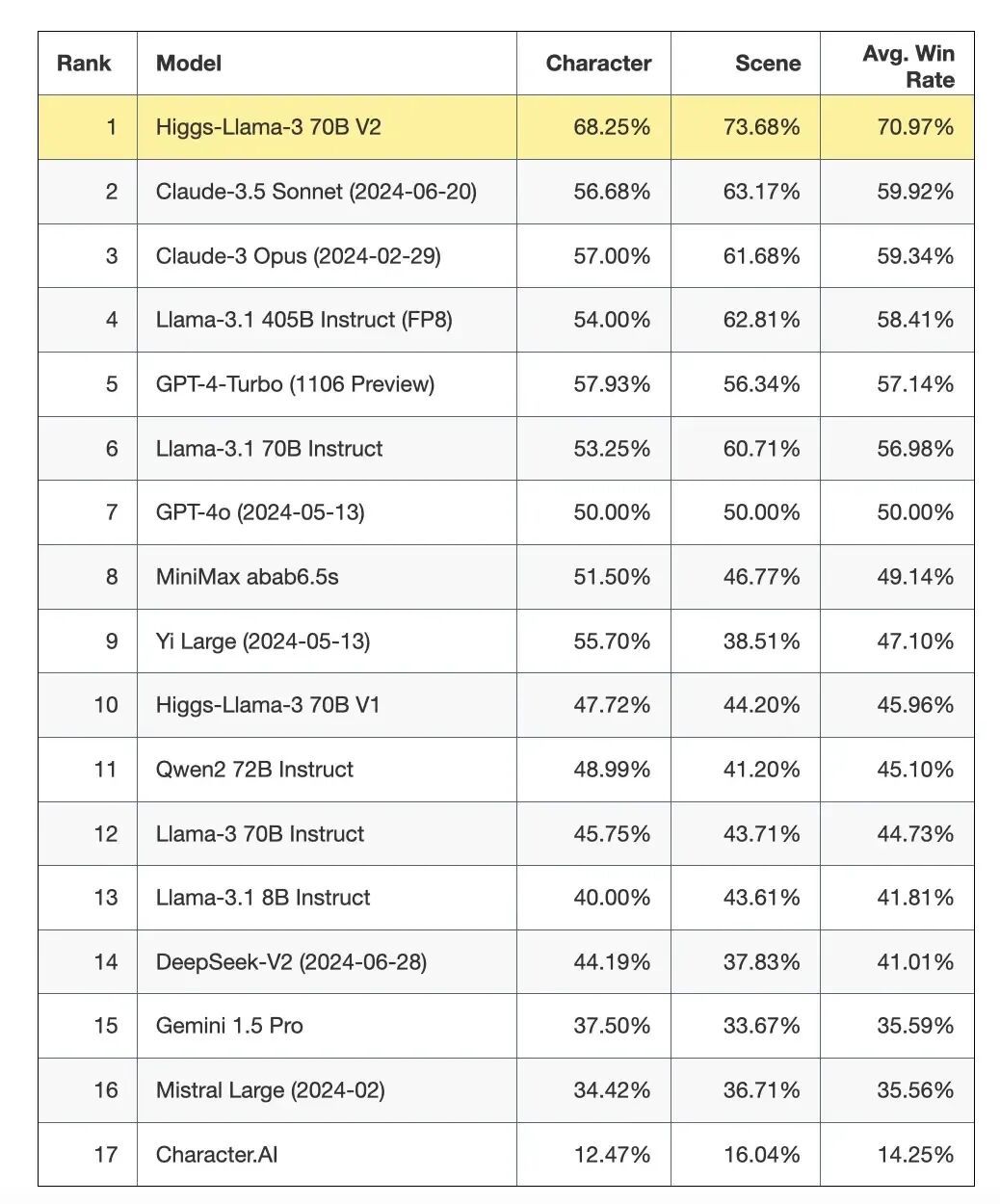
我在第四阶段的认知是,好的垂直模型的通用能力也不能弱,例如 reasoning,instruction following 这些能力垂直上也是需要的。长远来看,通用和垂直模型都得朝着 AGI 去,只是垂直模型可以稍微偏科一点,专业课高分,通用课还行,所以研发成本稍微低一点,研发方式也会有所区别。
第五阶段仍在进行中,希望能很快和大家展开分享。
愿景:人类陪伴
说来惭愧,我们并未在一开始就树立愿景,而是一门心思提升技术,给客户做定制,在过程中才慢慢找到自己追求的愿景,去看客户想要什么、我们自己想要什么、未来可能需要什么。
多年前,我憧憬有个机器人保姆能帮我带娃、陪娃,因为带娃、陪娃对我而言很难,当时我也不太理解娃当前的认知和想法。另外我希望工作上有个非常厉害的虚拟助手能跟我一起发明新的东西。等我老了,我也想有很有意思的机器人陪着我。所以我对于未来的预测是,生产工具越来越发达,一个人将能够完成之前一个团队才能完成的事情,这会导致人类个体更加独立,大家都忙着追求自己的事情,从而更加孤独。
这些综合在一起,**我们把愿景定成了 “人类陪伴的智能体”——一个情商很高、智商在线的智能体。**换算成现实中的人的话,应该会是一个专业团队。例如你想让它陪你玩,那它是专业策划 + 演员;你想让它陪你运动,那么它就是鼓励师 + 专业运动教练;你想让它陪你学习,那么它能给你将不清楚的问题讲明白。模型的好处是,它能长期陪伴你,真的了解你,而且可以 “真心为你”。
不过目前的技术离这个愿景还挺遥远。当下技术只能实现陪着聊天,而且在很多场景下聊得也不可观,不仅内容匮乏,而且智商情商有时都不在线。这都是当下要逐步解决的问题。如果有小伙伴做这一块的海外应用,欢迎联系我们。
团队:有挑战的事情得靠团队
创业之后,我才真正意识到团队的重要性。之前在大厂工作的时候,我觉得自己是颗螺丝钉,团队成员是螺丝钉,甚至团队也是颗螺丝钉。真正开始创业,我才发现创业团队就是一辆车,车虽小,但能跑,能载重,转弯灵活,各个角落都能去。我们公司刚成立时,米哈游老蔡来看了眼,他看见我们团队所有人都在一间房子里,还感慨说小团队真好。
当然,“小车”也有不方便的地方,比如时刻要提防有没有“油”,遇到不好走的“路”,得小心别把“车”震散架了。小团队的每个成员都很重要,没有冗余,当一个人不给力,就可能导致一个“轮胎”没气。人很宝贵,走一个人就可能意味着少一个“轮胎”。
以前我上班时选项目会选自己能主导开发的,但这也意味着问题不是很有挑战性。**创业选了个很大的问题去做,只能全靠团队了。别看本文里用了大量的 “我”,其实工作都是团队做的。**如果没了团队,我可能得转行去卖课了。(笑)
个人追求:名还是利?
到目前为止,我都依靠跟着内心的声音做决定,无论是工作后再去读博、去做视频,还是去创业。而创业需要强烈动机的支撑,才能克服层出不穷的困难。这需要对自己的动机做更深入的分析,而动机要么来自欲望,要么来自恐惧。
十年前,我可能更热衷于名利,但到了我现在的年纪,金钱的边际效用于我而言已经不高,名声带来的情绪价值也已经很小。
且不说宇宙的浩瀚,单单在人类的历史长河中,一个人的存在也只是一粒沙,意外地到来,迅速地消失。地球上生活过一千亿人,绝大部分人不会在历史上留下痕迹。就连我家家谱上那上千人名,我几乎都不认识。
那么一个人存在的意义到底是什么呢?我小时候曾因为想不清这个问题而抑郁。**在我潜意识里,我想去创造价值,获得存在的意义。**我选择 “上进”,去提升自己的创造价值的能力;选择录长视频和写教材,创造教育价值;选择去写读博、工作、创业的总结,描述里面的纠结和困难,创造事例的价值;选择去创业,团结很多人的力量去创造更大的价值。
后记
去年我和宿华在斯坦福散步,他拍着我肩膀说:“跟我说句实话,你为什么想创业呀?” 当时候我还不以为然:“就是想换个事情做做。”然后宿华笑而不语。
现在我懂了他的言外之意,因为他经历了创业的酸甜苦辣。如果今天再让我来回答这个问题,我会说:“我就是脑子抽了。”
不过我也庆幸自己当时没想到会那么不容易,所以才一头扎了进来。否则,大家今天看到的可能就是「工作十年反思」而不是「创业一年回顾」。我还是觉得今天我写的创业故事更有意思些。
最后,致敬所有创业人。

